
{kind=link}
Introduction: A Hall, Many Voices, and One Clear Goal
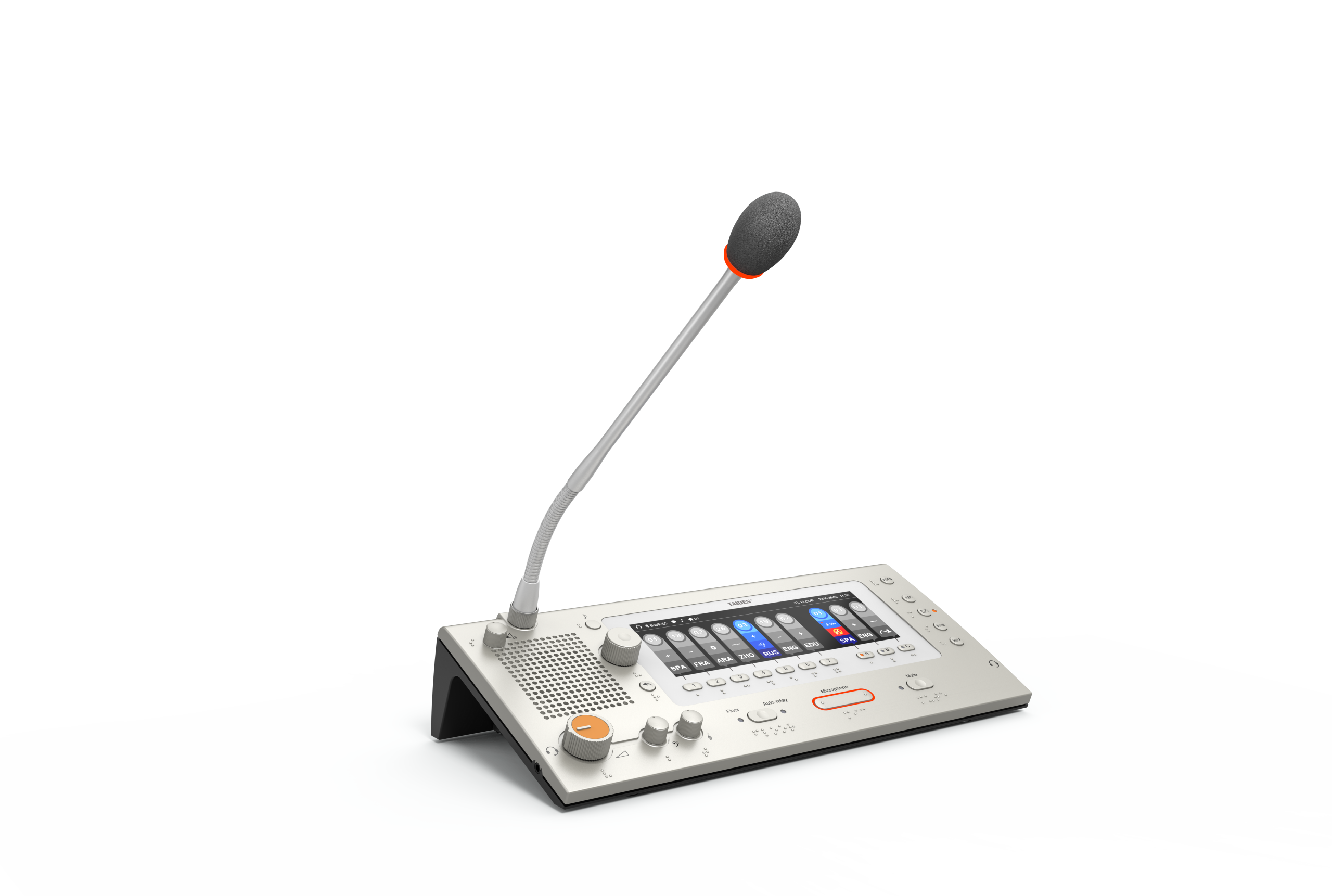
Picture a packed conference hall. The keynote switches languages mid-thought, and hundreds of headsets click as listeners chase clarity. Your interpretation system sits at the centre of it all, routing words, tones, and timing like a quiet air-traffic controller. Now here is the rub: research shows that even a 120–150 ms delay can reduce comprehension, and a single garbled handover can spike listener drop-off by double digits (small numbers, big impact). Are your channels helping, or are they adding friction at scale?

We will compare how setups cope when stress hits—side debates, Q&A, overlapping feeds. We will weigh where reliability really comes from, and what to improve next. Onwards to the hidden layer.
Under the Hood: Where Multi‑Channel Delivery Gains—or Loses—Clarity
When multi channel audio drives every booth and floor feed, the weak points show fast. The first is coordination. Many systems treat each channel as a silo, so the DSP pipeline, gain structure, and codec settings drift per line. That blows the latency budget when traffic surges. Next is the RF spectrum plan: crowded bands create crosstalk risk, so you need guard intervals and tight channel spacing. Add network jitter on top and you get tiny pops that break attention. Look, it’s simpler than you think: align processing stages across channels, not per box; handle buffering once, then fan out. Do that and your AES67 transport or Dante core behaves like a single spine—funny how that works, right?

Where do legacy setups fall short?
Older rigs prioritise channel count over synchrony. They chase “more outputs” but ignore phase coherence across headsets. Users feel it as fatigue, not failure. Interpreters feel it as uneven sidetone. Facilities see it as hot racks and stressed power converters. These are hidden pain points. They do not show on a spec sheet, yet they decide whether people stay with the stream or mentally check out after minute seven.
Comparative Future: Principles That Make Next‑Gen Interpretation Work
From here, think forward-looking rather than reactive. New designs stitch channels together with shared clocks, adaptive jitter buffers, and cross-channel loudness control. That keeps voices aligned when speech gets fast. Smart codecs scale bitrates per scene, so a whisper and a shout land within the same comfort zone. Edge computing nodes do the heavy lifting near the booth, then a lean core fans out to rooms and streams. The result: fewer drops when seats fill, and cleaner handovers during fast multilingual interpretation rounds. It is not magic—just better engineering choices applied to human listening limits.
What’s Next
Let’s tie the lessons together. We saw that per-channel tweaks create uneven timing; shared processing restores flow. We saw that RF and network jitter punish long chains; short paths and QoS tags keep packets on time. And we learned that fatigue is a metric, not a mood. If you need a quick, practical yardstick, use this advisory trio: 1) Synchrony: measure inter-channel latency variance under load (target sub-20 ms spread). 2) Intelligibility: track word error rate during fast speech and accents, with and without noise gating. 3) Resilience: test packet loss at 1–3% and log recovery time to stable audio. Choose the system that scores steady on all three, then grow your rooms from there—small steps, big gain. If you want a benchmark reference point from the field, have a look at how established conference platforms like TAIDEN structure their signal paths and timing discipline.